


Photo by Manuel Geissinger from Pexels
A frequent question in Alteryx demonstrations is ‘what is the row limit?’ - to which we can answer, that there isn't one! However, Alteryx’s ability to crunch through your data can be limited by a few things;
- How much you’re asking it to do
- How many columns and rows you’re asking it to do these things on
- The machine that you’re doing this on
Some of these things are harder to fix than others, as most people cannot pick out RAM for their computers as one might do a pair of shoes in the morning. However, there are things you can do to ensure that you aren’t hampered by billions of rows across fifty columns.
Top Tip: Think like a scientist by sampling your data.
My key advice when dealing with massive data sets is to build out your workflow with a sample as much as possible. 5% or 10% of your data can provide a significant amount of your data’s structure and variation to clear the major preparation tasks out of the way.
How best can I sample my data?
SQL Option
If you’re using SQL, you can sample your data in your query by using a LIMIT clause, which will skim N number of rows off your data. If you’d like a potentially more varied sample (such as a random sample), you can wade into this discussion between some SQL experts on Stack Overflow.
All Data Sources, including SQL
Use the Record Limit in the Input tool to limit the number of records Alteryx reads in, in a similar fashion to the LIMIT clause above. This setting is quite easy to sail past when configuring the input tool, but it is there (highlighted below).
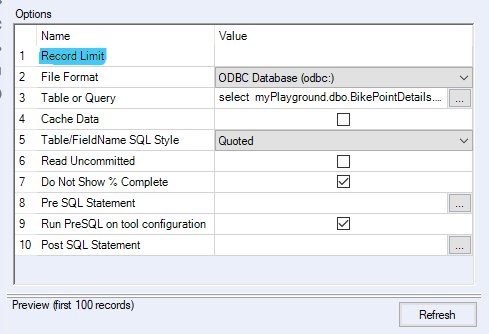
The reason I’m not suggesting using a sample tool after your input, though that is also fine, is because your workflow still has to load everything in the input, which isn’t very efficient.
#2 Tip: Drop (almost) everything
Unless you have a very organised data structure in your organisation, it’s very common to face tables and files which contain too much information for the business question you are trying to answer. This might be because the data set contains too many observations, or because it records a lot of detail you don’t need. When working with big data, it’s important to file down your data to what you require as fast as possible, such as using a Select tool to drop columns or a Filter tool to drop rows which aren’t required. Remember, you can use tools like Join and Summarize to add detail back into your data when you need it.
#3 Tip: Check your Schedules
Once you have built your workflow with your sample, tested it on a larger sample to ensure it’s as efficient as it can be, and UATed it with your business stakeholders, it’s ready to be put into production. With Alteryx, jobs like this tend to be scheduled on Alteryx Server, because no one wants some kind of million row transactional consolidation chunking along their own computer during a sprint meeting. So, let’s schedule it for 2am, right?
No, or at least, not quite.
It is important to check the job schedule of both the Alteryx Server and the data source you are using (which is likely to be another server, if a big data set). Both of these servers likely already have jobs scheduled on them by your co-workers and administrators, so although the small hours of the morning often sounds like the best time to do a frequent big data run, make sure you schedule your workflow at a time it won’t bump into other people’s work.
Why haven't you suggested caching?
A few joyful versions ago, Alteryx introduced a feature called 'caching', which you could select a point in your workflow, run it, and 'freeze' the data processing up to the point selected. The reason why I've not added caching to this list is because of the answer to the question, where is that data frozen? Although caching is a really handy feature that I use all the time, when I am using datasets with tens of millions of rows, caching that data means it's being held in your machine's memory - which you need to build the rest of your workflow, look things up on the Alteryx Community and send gifs to your co-workers.
Hopefully this has given you some tips about working with large data sets in Alteryx! If you have any suggestions, you can @ me on twitter.