

Definition of Type 2 SCD
There are a few variations on this but according to Wikipedia:This method tracks historical data by creating multiple records for a given natural key in the dimensional tables with separate surrogate keys and/or different version numbers. Unlimited history is preserved for each insert.
For example, if the supplier relocates to Illinois the version numbers will be incremented sequentially:
| Key | SCode | Supplier | State | Version. |
|---|---|---|---|---|
| 123 | ABC | Acme Supply Co | CA | 0 |
| 124 | ABC | Acme Supply Co | IL | 1 |
Another method is to add 'effective date' columns.
| Key | Code | Suppliere | State | Start_Date | End_Date |
|---|---|---|---|---|---|
| 123 | ABC | Acme Supply Co | CA | 01-Jan-2000 | 21-Dec-2004 |
| 124 | ABC | Acme Supply Co | IL | 22-Dec-2004 |
The null End_Date in row two indicates the current tuple version. In some cases, a standardized surrogate high date (e.g. 9999-12-31) may be used as an end date, so that the field can be included in an index, and so that null-value substitution is not required when querying.
Alteryx Solution
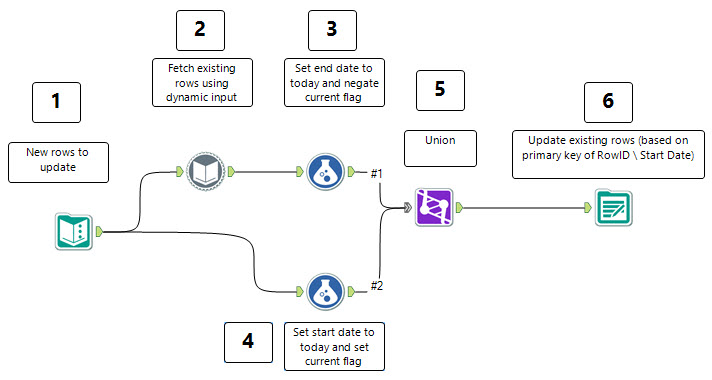
The data, I used start / end dates and also a version flag to show which was current (initially everything is current), a variation of that shown in the wikipedia article above:

The steps I took:
1. Import the data I want to import (in this case I used a Text Input tool but you could use any data source that matches the data table you need to import )
2. Use a Dynamic Input tool to connect to the current data that already exists, in this case I want where the [Row ID] is in my input data (i.e. I'm updating that row) and where it is the current row (I used a [Current] flag set to 1 for that but have equally checked where the End Date was 2099-12-31 - the default).
If you aren't familiar with it the Dynamic Input tool can be used in many ways, in this way I am using it to only return certain rows of a much larger table. In order to do this I first define a sample Input, using what looks like a standard input option, in this case I connected to a database and used the following query:
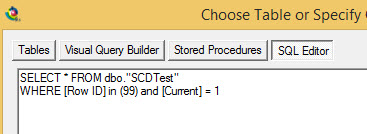
i.e. selecting the Current row and using 99 (more on why in a sec) for the [Row ID] (our primary identified of the rows in this case)
Next I chose to update the 99 dynamically based on the rows we're actually updating, to do this choose the Modify SQL Query option and choose Update Where Clause in the drop down:
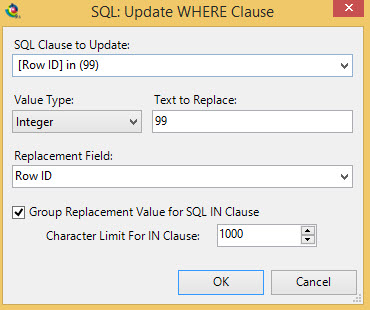
I want to update that 99 part of the query and change it to the values in our database, Grouped into a IN clause (e.g. if there are values 1, 2 and 3 it will replace the query with WHERE [Row ID] in (1,2,3) and [Current] = 1
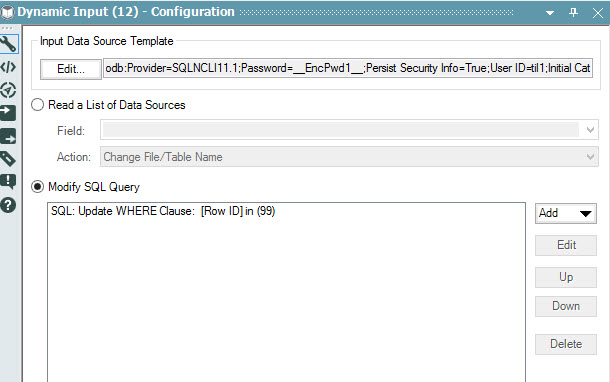
Here's what the tool looks like when I'm done:
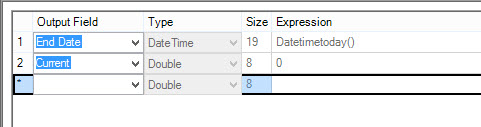
3. These existing rows from the table need an end date of today and also need the current flag setting to 0 so they are no longer current. Simple formulae to do that:
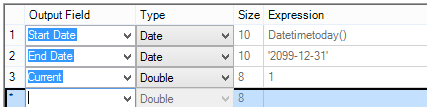
4. In a similar way we need to add those fields on to our new data, but the start value needs to be today, with default end date and a Current flag of 1 to show the data is new.
5. We union the data to get it into one stream
6. We update existing rows and insert new rows using the output tool to the database:
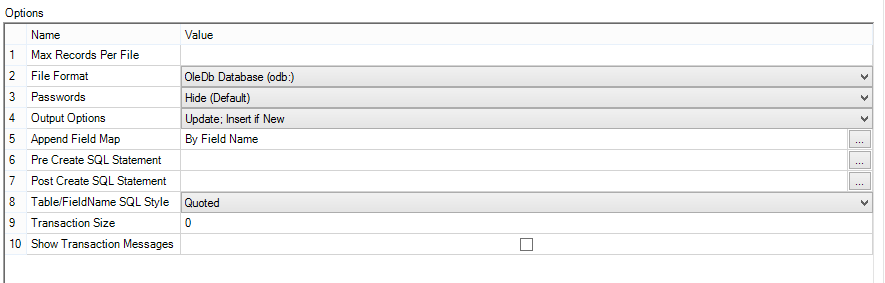
Option 5 being the key one here, using the Update / Insert option we use the databases primary key (which in this case is set to Row ID Start Date - which is a unique combination) then it will update the existing rows (updating the current and end flags we set) and also insert the new rows.
The result:
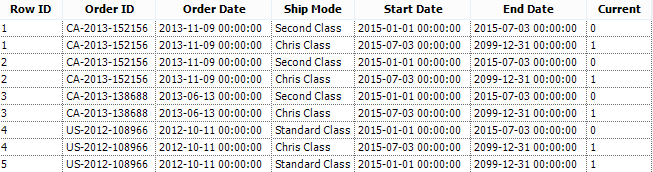
I hope this makes sense, feel free to contact us if you have this requirement and can't follow the above logic.