

I'm sure the following scenario is familiar, at least to some.
You've built an Alteryx workflow, it works great, but then, your data provider (usually an individual who has promised the data structure will never change) decides to change the structure of the incoming data source, a column name change or a dropped column, something that breaks our beautiful Alteryx masterpiece.
You then spent an hour rebuilding your workflow to cope with said file.
Well, I'm going to show a neat trick, which puts the onus back to your data provider to provide you with a consistent datasource.
The workflow below shows a complete version of what we'll be creating.
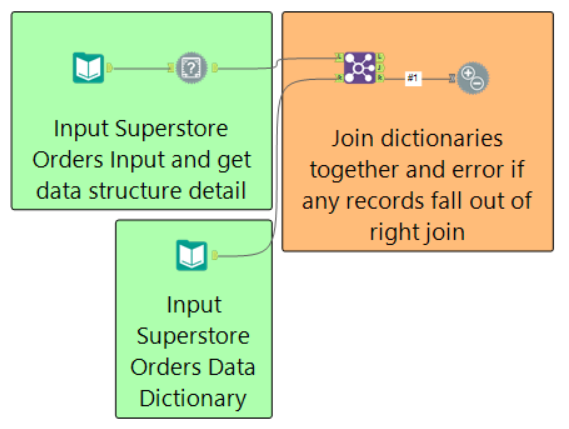
As a high level overview, we are taking the datasource provided by our annoying user; we are taking a data dictionary that we took when the project went into production, and we are testing whether the structure (field names, data types, and field lengths), is the same.
The test tool will error if any records pass into the right join, which indicate items that exist in our data dictionary, but do not exist in the latest dataset provided to us.
Now rather than bending our backs fixing this; we can now email the data provider and outline that the file does not meet the requirements, and also give the detail regards why (heck, we could even automate this email if we wished!).
So how do we set this up?
Well our first step is to build our data dictionary of the datasource we want to check, capturing the name, data type, and length of all fields; this is a relatively trivial task and can be done by using the 'Field Info' tool.
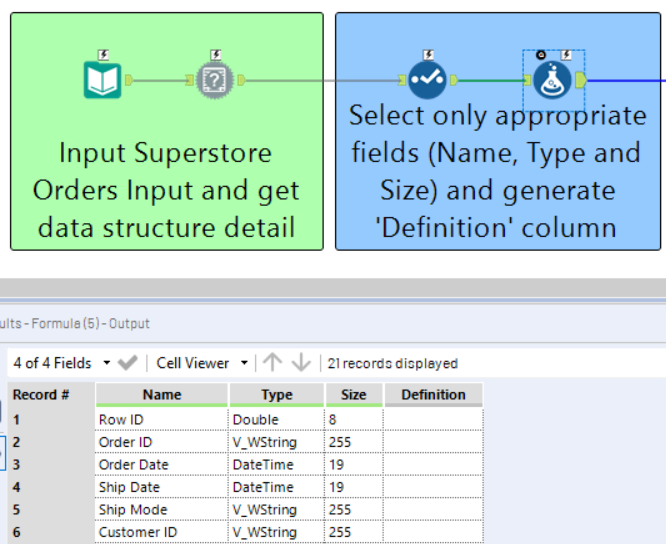
As this is an easily repeatable task across many datasets, I've created an application, available here, which allows you to simply specify your input file and output file, and it will generate the file on your behalf.
You may notice the 'Definition' column; this is a dummy field I have added (via the formula tool seen above) so that definitions can be added to the xlsx file manually, in order to provide any users with an understanding of what each field actually means.
The next step is building out this test workflow.
Let's start by bringing on both our actual workflow input onto the canvas, and our data dictionary of said input.
With our actual workflow input, we need to add a field info tool to capture the latest file structure.
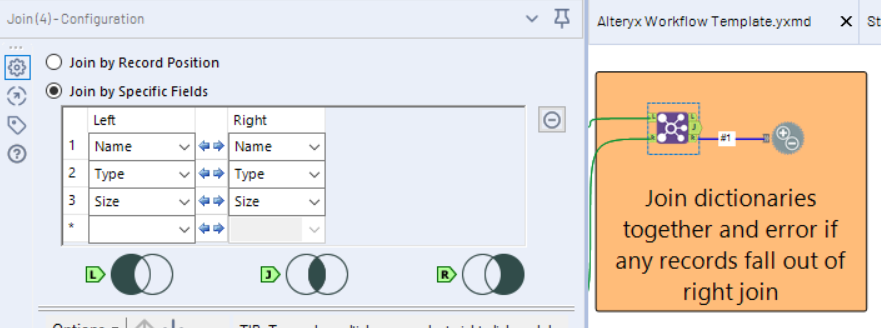
By joining these two streams together, on the key fields 'Name', 'Type' and 'Size', the following rules will apply;
L - this anchor will contain fields (whether that be because of Name, Type or Size (or a combination of those)) in our latest input file which are not contained in our data dictionary as per our desired input structure.
J - this anchor will contain fields which match on Name AND Type AND Size, this is our good data feed!
R - this anchor contains our problems, it will show instances where fields have not been identified (whether that be because of Name, Type or Size (or a combination of those)) in our latest data file, and therefor our workflow may error.
As the R or right anchor contains our problems, I have attached the 'Test' tool to this anchor, which allows us to trigger an error message should such a test fail.
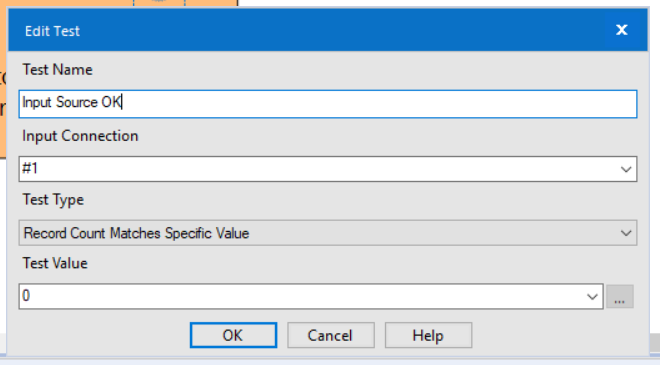
The test tool is really simple to use; you start by giving a 'Test Name'. I tend to use an 'inverted statement' due to the nature of how the Test tool reports errors..

We are then performing a test whether the record count, coming out of our right join output anchor, should be a specific value, which we have set to 0.
Therefor, if the record count is not 0, then the error will be triggered.
And that's it, it's really that simple!
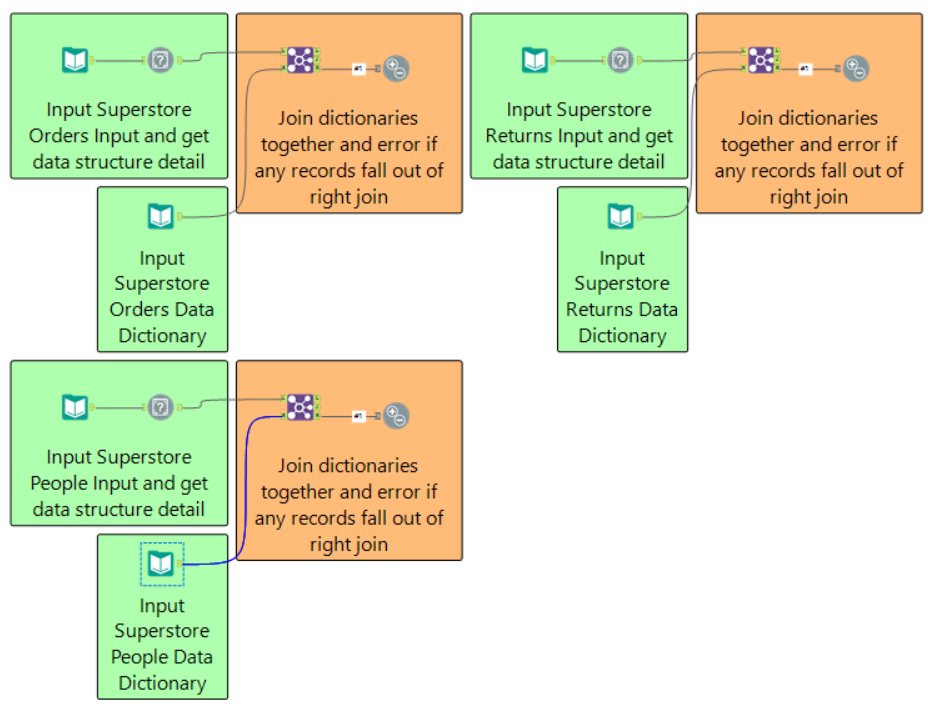
In a real word scenario you may have a 'Test' workflow which contains such tests for each of the inputs in the main workflow (as shown below). You may even use the 'Conditional Runner' tool, which forms part of the CReW macro pack, to run your test workflow prior to running your master workflow (which only runs if the test workflow does not fail).
The example in this post can be found here.
We may even develop this logic further; for example we may wish to test whether there are only certain categorical values in a field, or we may want to see if all of the values in a field are within a set range, say between 0 and 1000.
You may delete certain items from your data dictionary which simply aren't necessary fields for your workflow to run correctly.
But hey, I'm not going to ruin your fun and show give you the answer, have a go yourself!
Ben