


Background
dbt is great. Tableau is great. They work really nicely together. dbt's auto-exposures are an especially nice feature allowing to automatically update your DAG to see when there are published views connected to your carefully constructed tables. Or also to see if there are views connected to immature data.
However there was a piece of the puzzle missing for me. I can run a dbt job to update my data pipeline, but I can't automatically refresh any Tableau Extracts connected to that pipeline. Instead I have to rely on scheduling my Extract Refresh to occur after I think my dbt job will have finished.
But this needn't be the case. If dbt can see what part of the DAG a Tableau dashboard is connected to, and Tableau's Metadata API makes it possible to link dashboards to datasources, and Tableau's Rest API lets you trigger an Extract Refresh on demand; then I wanted to close the loop and set up a system which would automatically trigger an Extract Refresh once a dbt job had successfully completed.
This blog goes through my approach for completing the puzzle and automating Extract Refreshes based on successful job completions in dbt. I'll talk through the approach in a tool agnostic way, and then show how I implemented it in n8n.
(My approach uses auto-exposures to find all connected dashboards and trigger all connected Extracts. If you want to be more specific and only trigger a known list of Extracts, then dbt have a guide to doing that available here:)
TL;DR Just Give Me The Solution
Here's my n8n flow
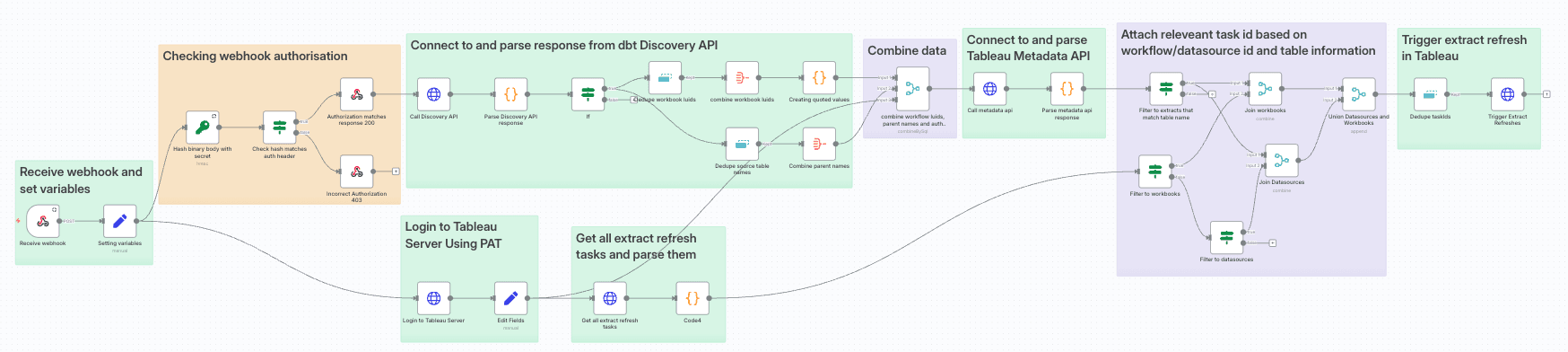 I've linked the code behind it here which you can copy/paste into n8n.
I've linked the code behind it here which you can copy/paste into n8n.
N.B. Before You Paste And Go
I set variables in the second step of my flow. This was to make it easy to share but it is not best practice. Some of the variables are tokens/secrets which absolutely should not be stored in plain text. If you implement this approach, I strongly urge you to use n8n's credentials or a secret manager/secure approach to input these values, rather than the insecure way in this sharing flow.
Webhooks
I knew this project would start with Webhooks. Webhooks are kinda like API calls, except instead of you deciding to connect to an API and get some information, Webhooks are sent automatically from a service once an action has occurred.
dbt platform has the ability to send a Webhook when one or more of 3 actions has occurred:
A job has started
A job has completed
regardless of if it errored or was successful
A job has errored
You can choose some or all of the configured jobs on the account to trigger the Webhook. In my case I had a couple of jobs doing incremental and full-refreshes of a particular section of the project DAG. So I created a Webhook which would be sent when either of those jobs had completed.
The Webhook sends a JSON payload like the one below to a specified url.

Not a huge amount of information, but there are some nuggets in there. Crucially we can use the runStatus to ensure that the job completed successfully. We can also get the Environment, Job and Run IDs which we can use in the dbt Discovery API to find out more information about what was actually run.
Discovery API
The dbt Discovery API is a GraphQL API that provides information about the metadata produced by a dbt run. It has a whole host of capabilities/use cases, and let's you answer questions about run performance, data quality, governance and discovery.
For my purposes it's perfect as it lets you look within a specific environment, find all the exposures configured and filter them just to dashboards. It can then show you the parent models/sources for those exposures, and also find out the last time they were run/tested for freshness and whether that run was successful, or that freshness check was passed. The other crucial metadata you can expose is for all of those parent models/sources, the Job ID and Run ID which ran them/tested them, and also for any auto-exposures, you can find the Resource ID of that dashboard generated from Tableau. This is all the information I need to link dbt to Tableau.
Unlike Rest APIs, where you have multiple endpoints which serve different information. GraphQL APIs have a single endpoint that you query with a JSON payload specifying exactly which information you want.
This is the query I created to get the information I wanted:
query RelevantStuff($envId: BigInt!, $first: Int){
environment(id: $envId) {
applied {
exposures(first: $first, filter:{exposureType: "dashboard"}) {
edges {
node {
name
url
uniqueId
exposureType
meta
parents {
name
... on ModelAppliedStateNestedNode {
executionInfo {
lastRunStatus
lastJobDefinitionId
lastRunId
}
}
... on SourceAppliedStateNestedNode{
freshness{
freshnessStatus
freshnessJobDefinitionId
freshnessRunId
}
}
}
}
}
}
}
}
}This uses 2 variables [envId] and [first].
[envId] can be set to the dbt environment found from the webhook, and [first] can be set to 500 (the maximum value) to find the first 500 dashboard exposures within the environment. I've assumed there are fewer than 500 auto-exposures, but if that's not the case, then you would need to paginate through the API which is outlined here.
The result of the above query is a JSON body that looks like this: (annotated with key fields circled in purple)
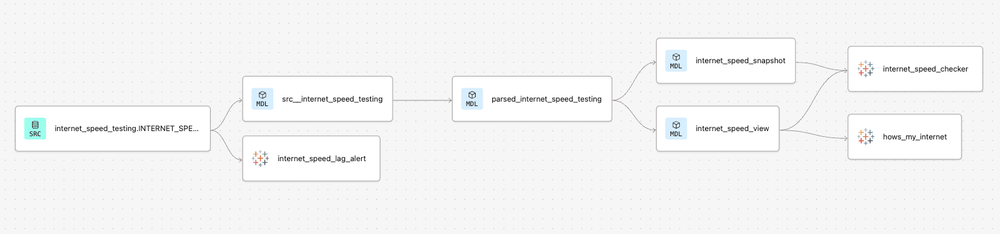
 This response shows 2 workbooks found as auto-exposures. The first, "internet_speed_checker" is connected to 2 models "internet_speed_snapshot" and "internet_speed_view". The second, "internet_speed_lag_alert" is connected to 1 source "INTERNET_SPEED_TEST".
This response shows 2 workbooks found as auto-exposures. The first, "internet_speed_checker" is connected to 2 models "internet_speed_snapshot" and "internet_speed_view". The second, "internet_speed_lag_alert" is connected to 1 source "INTERNET_SPEED_TEST".
We can use the purple circled values as follows:
The "dbt_cloud_bi_resource_id" will let us link to Tableau APIs and find the specific workbook.
The parent "name" will let us filter to the relevant Data Sources connected to that workbook, if there are multiple.
The "freshnessStatus" and "lastRunStatus" will let us focus on the tables which have been updated.
The "freshnessJobDefinitionId" and "lastJobDefinitionId" can be linked to the Job ID given by our Webhook response from earlier.
Likewise the "freshnessRunId' and "lastRunId" can be linked to the Run ID given by our Webhook response from earlier too.
A small note on sending GraphQL API requests
The JSON query outlined above works very nicely when using a GraphQL client (such as Postman or Apollo), but if we're sending API calls ourself, then we do need to be a bit careful about the formatting of it.
That query will be sent as the value of a "query" header in a JSON payload. This means it will be wrapped in double quotes and prepended by 'query ', so any double quotes within our JSON (such as those around the dashboard filter) need to be escaped with a backslash (\).
Any variable values will be passed again as a value object of a "variables" header.
I also found that removing newlines and duplicate whitespace helped sending the query.
To take the query above, and include the variable values of 444444 for the [envID] and 500 for [first], we would send a payload like this:
{"query": "query RelevantStuff($envId: BigInt!, $first: Int){ environment(id: $envId) { applied { exposures(first:
$first, filter:{exposureType: \"dashboard\"}) { edges { node { name url uniqueId exposureType meta parents { name
... on ModelAppliedStateNestedNode { executionInfo { lastRunStatus lastJobDefinitionId lastRunId } } ... on
SourceAppliedStateNestedNode{ freshness{ freshnessStatus freshnessJobDefinitionId freshnessRunId } } } } } } } } }",
"variables": { "envId": "444444", "first": 500 }}Tableau Metadata API
Sticking with GraphQL APIs, we now come to the Tableau Metadata API. Like the dbt Discovery API, this surfaces metadata about your Tableau Server/Cloud instance. It provides incredibly rich information about the views, dashboards, workbooks, Data Sources, virtual connections or other content on your Tableau Server/Cloud instance.
Again, as a GraphQL API we need to construct a query that we can send to the API specifying exactly what information we want.
We're going to use the "dbt_cloud_resource_id"s output from the dbt Discovery API call to filter to just the workbooks identified as auto-exposures. We can then find the Data Sources connected to those workbooks (whether published or embedded). For those Data Sources, we can get their name, whether they contain Extracts, the luid (if it exists) and also the names of the tables those Data Sources are based on.
query workbooksToSitesAndDatasources{
workbooks(filter:{luidWithin: ["<dbt_cloud_resource_ids_go_here>"]}) {
luid,
name,
upstreamDatasources{
name,
id,
luid,
hasExtracts
upstreamTables{
name
}
},
embeddedDatasources{
name,
id,
hasExtracts,
upstreamTables{
name
},
}
}
}Ultimately we need the luid of our Data Sources, if it's published, then it has its own luid; if its embedded then we can use the luid of the workbook in which it's embedded
The raw API payload of the above query (filtered to workbook luids 1234 and 5678) would look like this:
{"query": "query workbooksToSitesAndDatasources{ workbooks(filter:{luidWithin: [\"1234\",\"5678\"]}) { luid,
name,upstreamDatasources{ name, id, luid, hasExtracts upstreamTables{ name } }, embeddedDatasources{ name, id,
hasExtracts, upstreamTables{ name }, } } }"} This query returns a JSON body like this one: (again annotated with key information circled in purple)

So we've got 2 workbooks: "Internet Speed Checker" and "Internet Speed Lag Alert".
"Internet Speed Checker" has an Embedded Data Source which is built off 2 tables "INTERNET_SPEED_VIEW" and "INTERNET_SPEED_SNAPSHOT". This Data Source is an Extract.
"Internet Speed Lag Alert" is connected to a Published Data Source which is built off the table "INTERNET_SPEED_TEST". This Data Source is not an Extract.
Workbooks can be split into those connected to published Data Sources, and those connected to embedded Data Sources. (They can have both, but we're focussing on the Data Source, rather than workbook, so we can think of those instances as essentially 2 different workbooks).
The output of those workbooks connected to an embedded data source will have the Data Source name, an ID for it (crucially a different value than the IDs used by the Tableau Rest API), whether it contains Extracts, and the tables used by the Data Source.
The output of those workbooks connected to a published Data Source will have the Data Source name, an ID for it (again different to the Rest API ID), the Data Source luid (which is the same as the ID used by the Rest API), whether it contains Extracts, and the tables used by the Data Source.
If we combine these data we can filter to those Data Sources which are built off Extracts, and are connected to the tables which we identified using the dbt Discovery API. (In the case above, that would be the Embedded Data Source in "Internet Speed Checker" as it is connected to "INTERNET_SPEED_VIEW" which we saw earlier).
Having filtered to these Data Sources, we can then find the workbook luid or Data Source luid (depending if it's embedded or published) which we can use with the Tableau Rest API to trigger the immediate refreshing of those Extracts.

A Quick Detour To Talk About Extract Refreshes And APIs
Extract Refreshes behave a bit differently on Tableau Server compared to Tableau Cloud. Either way in order to trigger an Extract Refresh via the API, there needs to be an extant Extract Refresh Task on the Server/Cloud Site.
On Tableau Server, an Extract Refresh Task is made if the Extract Refresh is tied to a Schedule.
On Tableau Cloud, an Extract Refresh Task is its own thing that can be created. This task will always be run on a schedule (which is different thing to the Tableau Server Schedule).
The whole point of this exercise is trying to bypass the need for scheduled refreshes, in order to save costs, save time, and reduce data delays. The dream was to only refresh extracts once the data behind them has been updated, and to do so as quickly as possible. The need for Extract Refreshes to be tied to a schedule/scheduled task does undermine this a bit.
If you use Tableau Server rather than Tableau Cloud I have good news. While Tableau requires that an Extract Refresh be tied to a schedule, it doesn't require that schedule to be enabled. A Tableau Server admin has complete control over her schedules, so for the purposes of this endeavour, she can:
Create a new schedule
Name it something obvious
Set its frequency to once a month (the actual cadence doesn't matter)
Immediately disable it
Attach desired Extract Refreshes to that schedule
This means that we can still achieve our optimal Extract Refresh performance ✅
Sadly in a Tableau Cloud environment, it is not possible to disable an Extract Refresh Task (other than it happening automatically if the refresh fails 5 consecutive times).
I've thought of 2 approaches to this issue, a quick and easy one which reduces unnecessary refreshes; and a harder one which removes them entirely.
Quick, Easy, But Not Optimal
The lowest frequency you can set an Extract Refresh Task is once a month. You can choose which day of the month to run, so you could set your task to run on the 31st of each month. 5 months a year do not have a 31st, so it wouldn't run on those months. This would result in 7 unnecessary refreshes a year.
Optimal, But Faffy
The Tableau Rest API has endpoints for creating and deleting Extract Refresh Tasks. This means you could implement the following process
Create a Tableau Webhook which fires when an Extract is successfully refreshed (Workbook or Data Source)
Identify the relevant Extracts as above
Create an Extract Refresh Task for each of them scheduled for a time in the future (say tomorrow)
Check for confirmation that the Task was created and record its ID along with the Workbook/Data Source ID
Trigger the Extract Refresh Task to run now
Have a separate flow which receives the Tableau Webhook
Compare the luid from the Tableau Webhook payload with the recorded Workbook/Data Source ID to ensure the Extract Refresh Task has successfully run
Delete the Extract Refresh Task created in step 3.
I will leave implementing this as an exercise for the reader...

Tableau Rest API
Coming into this project, this was the API with which I had the most experience. However there are a couple of idiosyncrasies which it's worth going into.
The first step when using the Tableau Rest API is to sign in. This step will return a Site ID and a Token which we can use later. The Token it returns we'll use to authenticate with both the Rest API and also the Metadata API. This token goes in a header called "X-Tableau-Auth".
The Site ID will let us return all the current Extract Refresh Schedules which exist on a particular Tableau Server/Cloud Site. Unlike the Metadata API, which will scour your entire Server/Cloud instance, most Rest API endpoints are Site specific. Thankfully, currently dbt auto-exposures for Tableau are limited to one specified Site, so we know where these workbooks are going to be based. This means we know which Site to sign into, and which Site ID to use in all our calls.
Finding All Extract Refresh Tasks
We need to identify which Extract Refresh Tasks are linked to the Extracts we identified using the Metadata API. Sadly, currently we can't query a Data Source/Workbook to find its associated Extract Refresh Tasks. Instead we need to List all Extract Refresh Tasks on our Site.
As per the detour above, the response from this endpoint depends on whether you're calling Tableau Cloud or Tableau Server.
 We can compare the Workbook ID / Data Source ID with the luids found in the previous step to identify our Extract Refresh Tasks. We can then use the Extract Refresh Task ID to trigger it to run now.
We can compare the Workbook ID / Data Source ID with the luids found in the previous step to identify our Extract Refresh Tasks. We can then use the Extract Refresh Task ID to trigger it to run now.
Final Steps
We now have all the information we need in order to trigger these Extract Refreshes. Once we've isolated (and deduplicated) the Extract Refresh Task IDs we can simply call the Run Extract Refresh Task endpoint of the Tableau Rest API to trigger them.
We've reached the sunlit uplands of fully automated extract refreshes. The days of data delays, or bodgy scheduling are forever behind us.

The Flow
I've purposefully written this blog so far in an abstract way. I've talked about APIs and data values, but not how to implement the linking/filtering/calling. This is so you can use whichever tool/service you want, as you understand how these services connect.
The next section of this blog will be going through my n8n implementation, but before I do that, I'll finish off this abstract section by recapping how this flow works.

Receive the dbt Webhook
Ensure the run was successful
Use the Environment ID in the dbt Discovery API call
Parse the response and filter to exposures which are connected to models/sources involved in the Job and Run which triggered the Webhook. Also ensure that the models/sources were successfully built / are up to date
Use the Tableau Workbook luids of those filtered exposures in the Tableau Metadata API call
Parse the response and filter to workbooks which contain extracts, and are connected to the models / sources identified in step 4
Use the Tableau Rest API to list all Extract Refresh Tasks on the Tableau Site
Parse the response and filter to the Extract Refresh Tasks which have the same Workbook/Data Source luid as those identified in step 6
Ensure the list of Extract Refresh Tasks is unique
Use the Tableau Rest API to trigger a 'Run Now' for those unique Extract Refresh Tasks
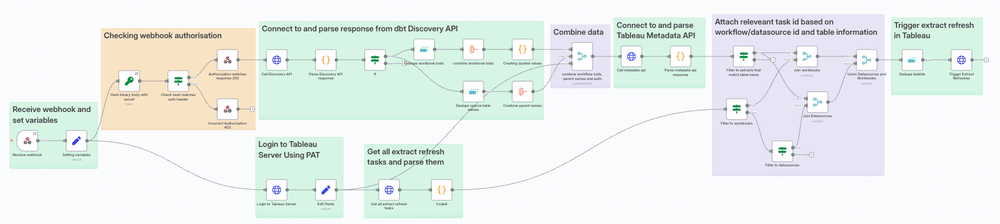
n8n Implementation
The flow above can be used in many tools. All you need is the ability to receive a webhook, to connect to APIs and to do some parsing/filtering. I used n8n as it ticked all these boxes, I had access to it, and
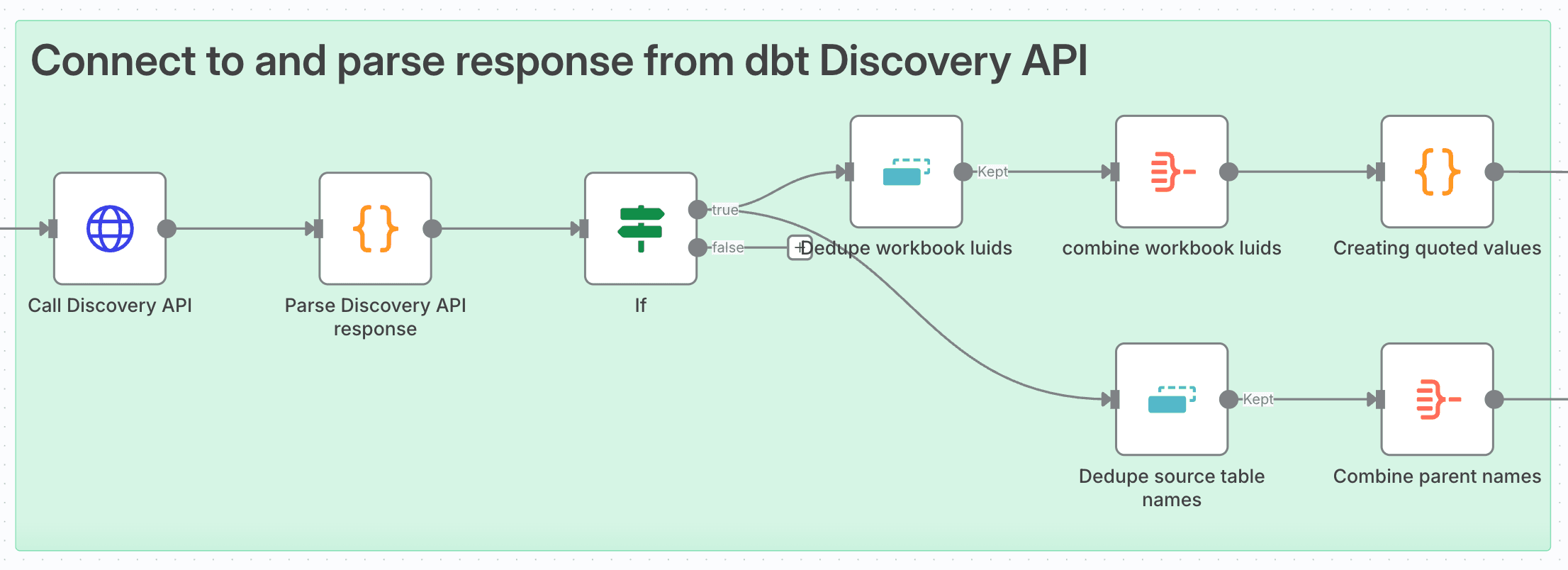
Connecting To, And Parsing dbt Discovery API
You can use an HTTP Request node to make API calls in n8n. For the Discovery API I needed a POST method to the constructed URL:
{{ $('Setting variables').item.json.dbtDiscoveryUrl }}/graphqlIdeally you'd want to set up credentials with your dbt Service Token as an Authorization header, but I used my insecure variable method. I manually created the header and set the value to:
Bearer {{ $('Setting variables').item.json.dbtDiscoveryToken }}Toggle on Send Body, set its content type to JSON and use the following JSON as your payload
{"query": "query RelevantStuff($envId: BigInt!, $first: Int){ environment(id: $envId) { applied { exposures(first:
$first, filter:{exposureType: \"dashboard\"}) { edges { node { name url uniqueId exposureType meta parents { name
... on ModelAppliedStateNestedNode { executionInfo { lastRunStatus lastJobDefinitionId lastRunId } } ... on
SourceAppliedStateNestedNode{ freshness{ freshnessStatus freshnessJobDefinitionId freshnessRunId } } } } } } } }
}", "variables": { "envId": {{ $('Receive webhook').item.json.body.data.environmentId }}, "first": 500 }}This is almost identical to the one earlier in the blog, except I'm setting the [envId] variable to the environmentId value given by the Webhook body.
I then needed to parse the response of the Discovery API in order to filter the exposures. n8n has a Code node in which you can use JavaScript or Python (in beta). I went with JavaScript and armed with Chat-GPT came up with the following code to take the raw JSON and turn it into a tabular form:
// In an n8n Function node
// Get the first input item (the HTTP Request response)
const data = items[0].json;
// Drill down to exposures
const exposures = data.data?.environment?.applied?.exposures?.edges || [];
const results = [];
for (const edge of exposures) {
const node = edge.node;
// Handle exposures with no parents gracefully
const parents = node.parents && node.parents.length > 0 ? node.parents : [{}];
// set empty variables
for (const parent of parents) {
let status = "";
let jobId = "";
let runId = "";
let parent_type = "";
//prioritise execution info over freshness for status, jobid and runid. Create parent_type based on source/model
if (parent.executionInfo) {
status = parent.executionInfo.lastRunStatus || "";
jobId = parent.executionInfo.lastJobDefinitionId || "";
runId = parent.executionInfo.lastRunId || "";
parent_type = "model";
} else if (parent.freshness) {
status = parent.freshness.freshnessStatus || "";
jobId = parent.freshness.freshnessJobDefinitionId || "";
runId = parent.freshness.freshnessRunId || "";
parent_type = "source";
}
//parse json
results.push({
json: {
exposure_name: node.name,
exposure_url: node.url,
exposure_uniqueId: node.uniqueId,
exposure_type: node.exposureType,
dbt_cloud_id: node.meta?.dbt_cloud_id || "",
dbt_cloud_bi_provider: node.meta?.dbt_cloud_bi_provider || "",
dbt_cloud_bi_resource_id: node.meta?.dbt_cloud_bi_resource_id || "",
parent_name: parent.name || "",
status,
jobId,
runId,
parent_type
}
});
}
}
return results;Having parsed the response, I can use another If node to filter the exposures to Tableau Dashboards that were linked to models/sources involved in the Webhooked job
 I used a Remove Duplicates node to dedupe Workbook luids and Parent Table Names (Remove Items Repeated Within Current Input). I then used an Aggregate node to convert these values into arrays.
I used a Remove Duplicates node to dedupe Workbook luids and Parent Table Names (Remove Items Repeated Within Current Input). I then used an Aggregate node to convert these values into arrays.
I now had two streams, one with an array of Workbook luids, and another with an array of Parent Table Names. However I needed the Workbook luids to be in a form that could be dropped into my Tableau Metadata API query body. In other words I needed each value to be wrapped in escaped double quotes. Back to Chat-GPT and then back to another Code node with the following JavaScript:
//creating a new column called quoted with double-quoted concatenated values
return items.map(item => {
const original = item.json.workbook_luid || [];
// Wrap each element in double quotes and join with commas
const quoted = original.map(v => `\\"${v}\\"`).join(',')
return {
json: {
workbook_luid: original,
quoted
}
};
});
Signing In To Tableau Server
Very straightforward. We're back to an HTTP request node to make another POST request. Again I used my variables to construct the URL:
{{ $json.ServerURL }}/api/{{ $json.APIVersion}}/auth/signinProperly no authentication this time, but we do need to set the Accept header to be Application/JSON (the default for the API is Application/XML, and I prefer working with JSON).
We're sending a body, which has the Content Type of Application/JSON, and pulls together the variables we set at the beginning of the flow:
{
"credentials": {
"site": {
"contentUrl": "{{ $json.contentURL }}"
},
"personalAccessTokenName": "{{ $json.PATName }}",
"personalAccessTokenSecret": "{{ $json.PATSecret }}"
}
}I then (optionally) used a Set node to simplify my data by just keeping the Token, ServerURL and APIVersion:
 I could use the token to authenticate with both the Metadata API and the Tableau Rest API, and I would need the ServerURL and APIVersion for my future Rest API calls.
I could use the token to authenticate with both the Metadata API and the Tableau Rest API, and I would need the ServerURL and APIVersion for my future Rest API calls.
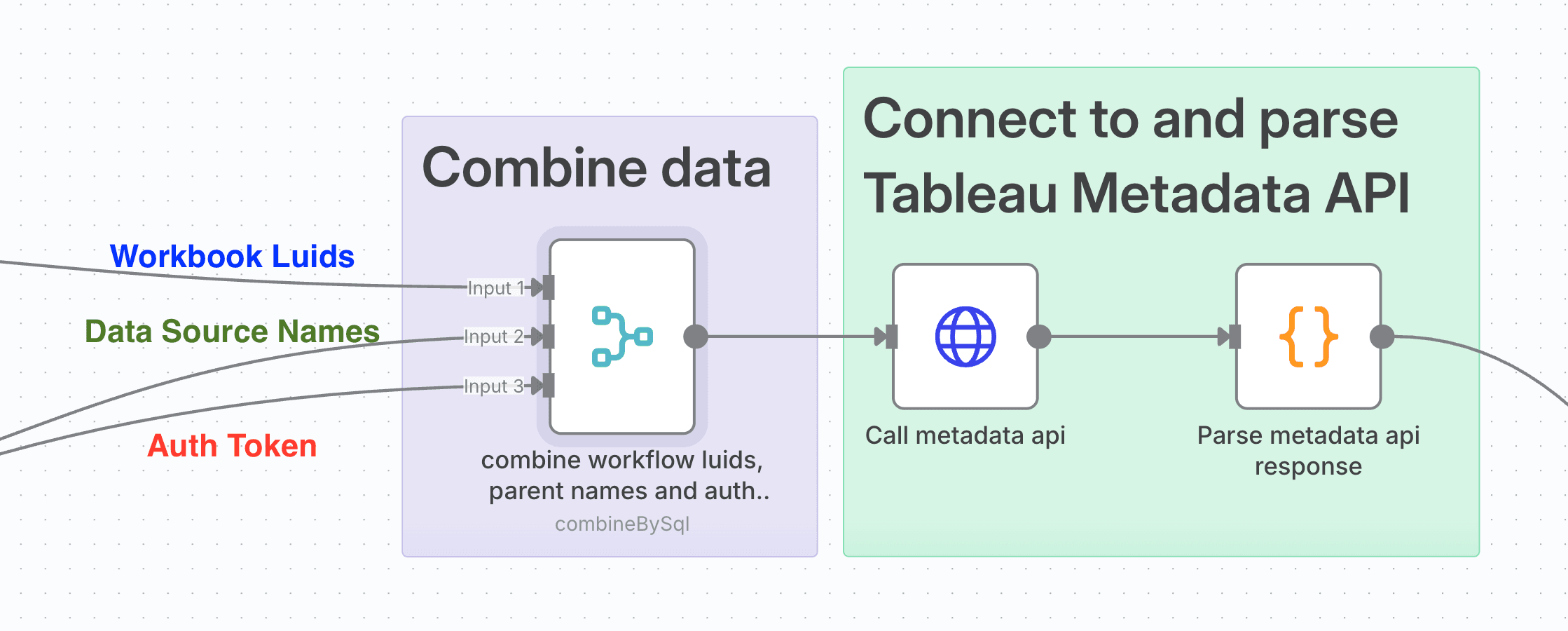 Combining Streams And The Metadata API
Combining Streams And The Metadata API
The Merge node in n8n lets you do joins and unions. I needed to create a single data set of my Workbook Luids (quoted), Parent Table Names and Auth token.
I used The SQL Query mode specifying 3 inputs and the following SQL to do this:
SELECT
a.workbook_luid
, a.quoted as quoted_luid
, b.parent_name
, c.token
, c.ServerURL
, c.APIVersion
from input1 a CROSS JOIN input2 b
CROSS JOIN input3 cI was now ready to call the Metadata API.
Very similar to before, we're using an HTTP Request node to make a POST request to our constructed Metadata API URL:
{{ $json.ServerURL }}/api/metadata/graphqlNo in-built authentication, but we need to make our own header called X-Tableau-Auth which has the value of the token from our merge. We can do this with an expression set to
{{ $json.token }}Then toggle on Send Body, set the Body Content Type to be JSON, specify the Body 'Using JSON' and use the following as the actual JSON body:
{"query": "query workbooksToSitesAndDatasources{ workbooks(filter:{luidWithin: [{{ $json.quoted_luid }}]}) { luid,
name,upstreamDatasources{ name, id, luid, hasExtracts upstreamTables{ name } }, embeddedDatasources{ name, id,
hasExtracts, upstreamTables{ name }, } } }"} Again, basically identical to the one explained in the first half of the blog, except for we're filtering to workbook luids which in our quoted array from the final step of the Discovery API section.
The final step is to parse the response of the Metadata API, so it's another Code node with vibe-coded JavaScript to turn our JSON into a tabular form with a row per Upstream Table. This code combines the Embedded Data Source and Upstream Data Source objects into a single Data Source Id, Name, hasExtracts, and luid (which is empty if an Embedded Data Source).
// n8n JavaScript code to transform JSON to flattened CSV structure
const inputData = $input.all();
const results = [];
inputData.forEach(item => {
const data = item.json.data;
data.workbooks.forEach(workbook => {
const workbookLuid = workbook.luid;
const workbookName = workbook.name;
// Process both upstream and embedded datasources
const allDatasources = [
...workbook.upstreamDatasources,
...workbook.embeddedDatasources
];
allDatasources.forEach(datasource => {
allDatasources.forEach(datasource => {
const datasourceId = datasource.id;
const datasourceLuid = datasource.luid || ""; // Empty string if no luid (embedded datasources)
const datasourceName = datasource.name;
const hasExtracts = datasource.hasExtracts;
// Process upstream tables - create a row for each table
datasource.upstreamTables.forEach(table => {
results.push({
workbook_luid: workbookLuid,
workbook_name: workbookName,
datasource_hasExtracts: hasExtracts,
datasource_id: datasourceId,
datasource_luid: datasourceLuid,
datasource_name: datasourceName,
upstreamTables_name: table.name
});
});
});
});
});
});
return results;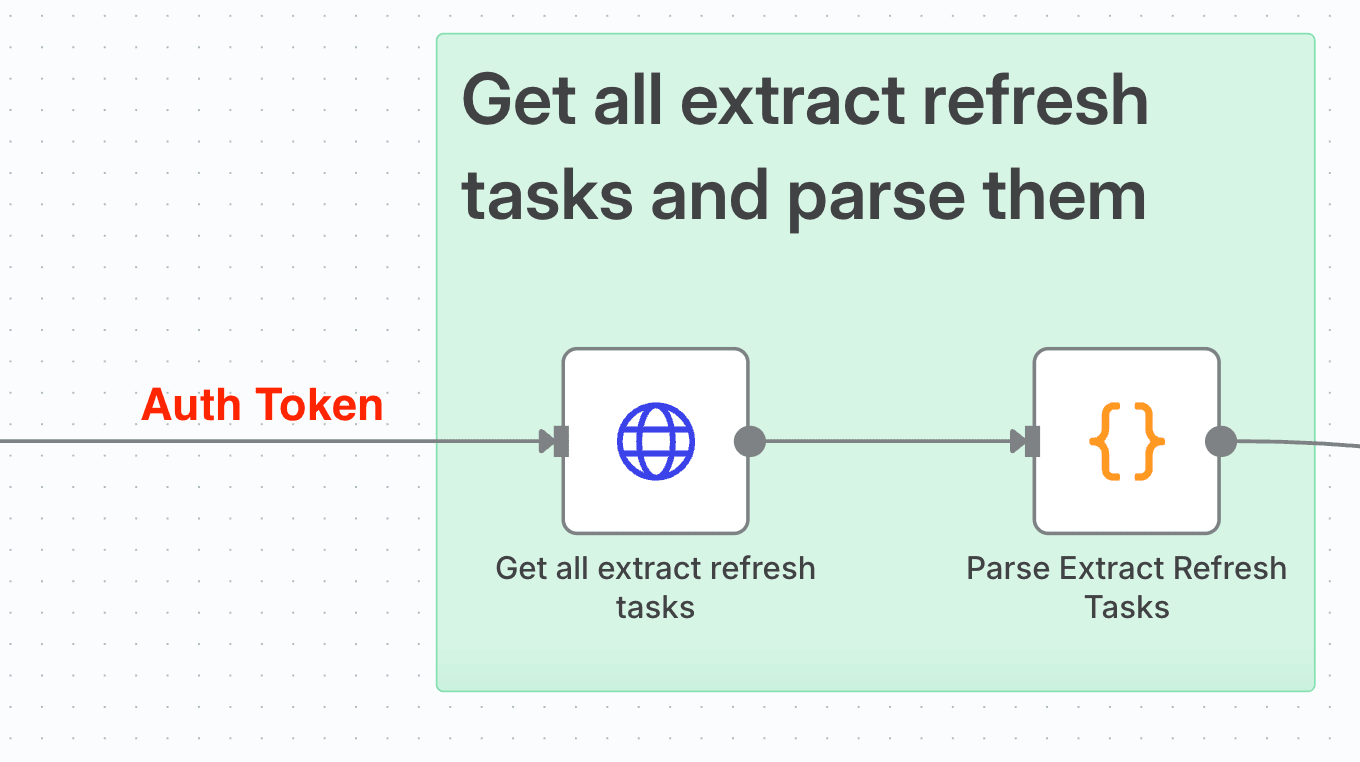 Get All Extract Refresh Tasks
Get All Extract Refresh Tasks
Working off the Set node from our Tableau Server Sign-In call, we need the token to authenticate with the Rest API. This time in our HTTP Request node, we're making a GET request.
We've got another constructed URL to give us 1000 Extract Refresh Tasks for our signed-in site:
{{ $json.ServerURL }}/api/{{ $json.APIVersion }}/sites/{{ $('Login to Tableau
Server').item.json.credentials.site.id }}/tasks/extractRefreshes?pageSize=1000If your site has more than 1000 Extract Refresh Tasks, then you'll need to paginate this call. How to implement pagination in the Tableau Rest API is outlined here.
As with the Metadata API call before, we need to add a header called X-Tableau-Auth with our token value, called as before with an expression set to
{{ $json.token }}We also need to set an Accept header to Application/JSON so we receive our response in JSON rather than XML.
Having received our tasks, we need to parse them, so for the final time we JavaScript in a Code node. I combined Data Source luids and Workbook luids into a single ItemId field, and distinguished them with an itemType field. I also parsed the TaskType, and of course the TaskId
// n8n JavaScript code to transform JSON to flattened CSV structure
const inputData = $input.all();
const results = [];
inputData.forEach(item => {
const data = item.json.tasks;
data.task.forEach(task => {
const extractRefresh = task.extractRefresh;
const scheduleId = extractRefresh.schedule?.id || "";
const scheduleType = extractRefresh.schedule?.type || "";
const taskType = extractRefresh.type || "";
const taskId = extractRefresh.id || "";
let itemType = "";
let itemId = "";
if (extractRefresh.workbook?.id) {
itemType = "workbook";
itemId = extractRefresh.workbook.id;
} else if (extractRefresh.datasource?.id) {
itemType = "datasource";
itemId = extractRefresh.datasource.id;
}
results.push({
taskType,
scheduleId,
scheduleType,
itemType,
itemId,
taskId,
});
});
});
return results;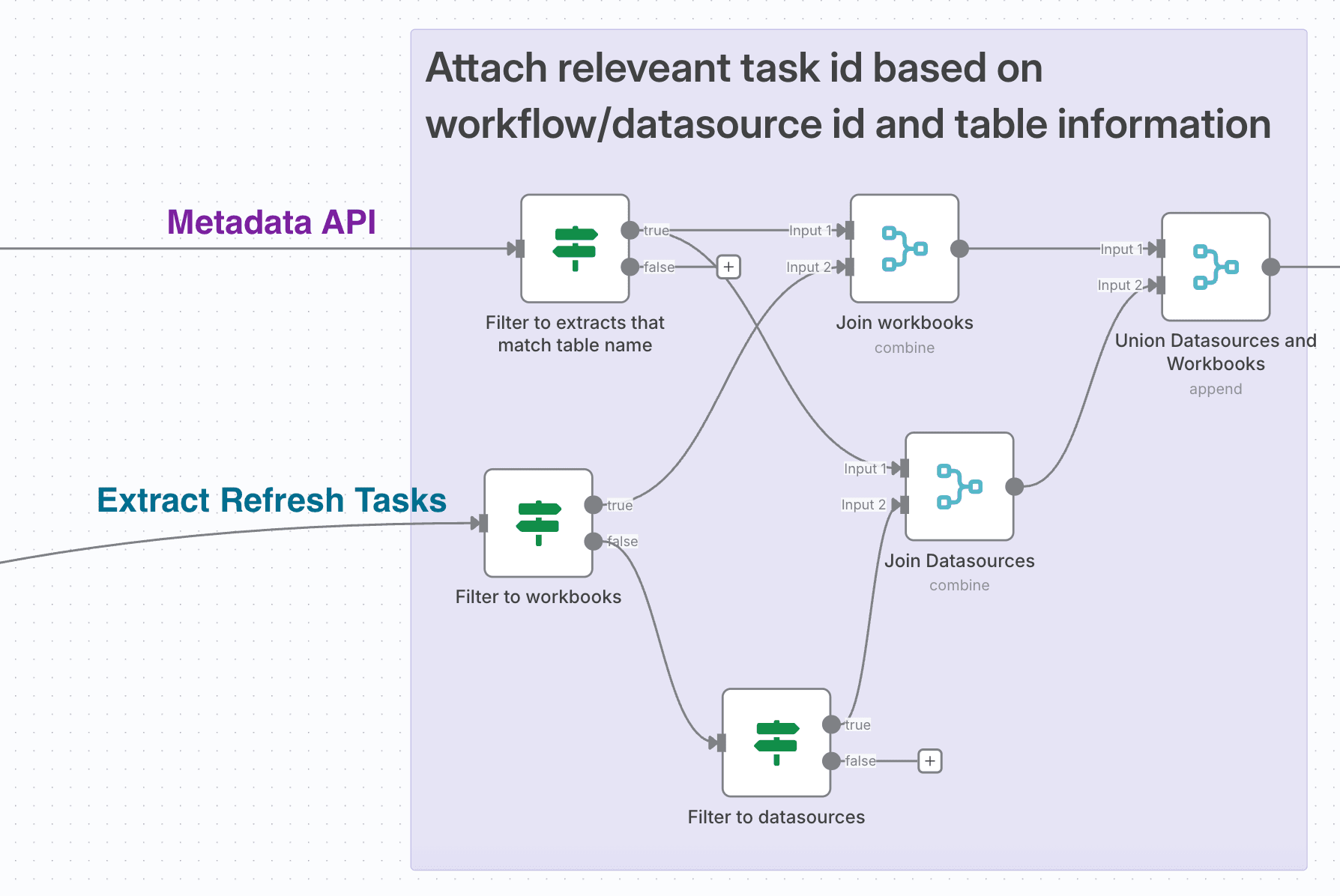 Final Filtering And Combining
Final Filtering And Combining
We need to filter our Metadata API response. We only want extracts, and those which are connected to tables involved in our dbt run. So working off the Metadata API stream, we can use an If node with the following conditions:

(hasExtracts is true and parent_name contains upstreamTables_name).
Now working off the Extract Refresh Tasks stream, we need to separate our Workbooks and our Data Sources. The itemType column can be used in a couple of If nodes to do this.
 (change workbook to datasource for the other node config).
(change workbook to datasource for the other node config).
We can use a Merge node to join the Workbooks onto our filtered Metadata API data using workbook_luid = itemId like so:
 An almost identically configured Merge node will let us match our Datasources onto the Metadata API when the datasource_id = itemId. All we need to change is our Input 1 Field to datasource_id.
An almost identically configured Merge node will let us match our Datasources onto the Metadata API when the datasource_id = itemId. All we need to change is our Input 1 Field to datasource_id.
Finally we can union the outputs of these two Merge node with a final Merge node. This one in Append mode with 2 inputs.
 Triggering The Extract Refreshes
Triggering The Extract Refreshes
And we're finally there. A Remove Duplicates node to deduplicate taskIds (Remove Items Repeated Within Current Input). And we now have our unique list of tasks to refresh our relevant Extracts.
A final HTTP Request node to make a POST request to a constructed URL:
{{ $('Edit Fields').item.json.ServerURL }}/api/{{ $('Edit Fields').item.json.APIVersion }}/sites/{{ $('Login to
Tableau Server').item.json.credentials.site.id }}/tasks/extractRefreshes/{{ $json.taskId }}/runNowWe need to set our X-Tableau-Auth header to our token from our Set node way back when:
{{ $('Edit Fields').item.json.token }}The runNow endpoint only takes a POST request, so we do need to provide a body. However the body doesn't really contain anything. In this case I'll use application/XML as the Content Type as the documentation is written in XML. We can't send an empty payload so instead we send:
<tsRequest> </tsRequest>and we're done!
