


If you orbit anywhere within the pull of the dbt ecosystem, you might have heard the name dbt fusion popping into conversations. And if you haven’t? Think of this as a quick glimpse into what’s appearing on the horizon.
So what actually is it? And how is it different to what we already had?
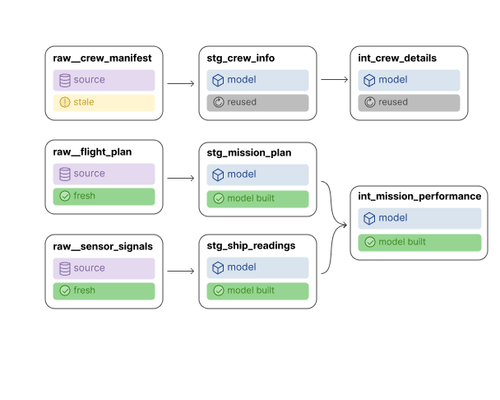
Before dbt Fusion, we had dbt Core. It brought much needed modularity to SQL. Gone were the days of excessively long scripts buried in stored procedures, and a new era of modular, version-controlled pipelines began. It allowed us to easily implement similar standards to those used in software development, bringing easily implementable testing and documentation as standard. Overall, it made data deployments significantly less anxiety inducing.
Built on Python, the dbt Core engine is nifty, but it essentially compiles the code and passes to the warehouse without explicitly understanding it and is almost more of a middleman. As enterprises fell in love with dbt and began to scale up and up, the sheer volume of models, metadata, and performance demands, began to stretch the capabilities of the Python engine fuelling it all.
As such, dbt needed a new kind of rocket fuel to maintain its trajectory across an ever-expanding data landscape.
dbt Fusion
What is it and how is it different?
New Engine - In a move away from Python, dbt Fusion’s engine is powered by Rust – which is itself built for high performance and concurrency. In comparison to Python, it can handle thousands of tasks at a time and can such reduce processing bottlenecks in larger scale projects.
Better Performance & Speed – With Rust powering the engine, parsing is much speedier, with command waiting around time slashed from minutes to seconds.
Understands your SQL – dbt Core compiles your code and executes against your warehouse, without actually understanding your logic whereas Fusion uses static analysis to read and understand your logic before it ever reaches the warehouse.
What is Static Analysis? Essentially, the engine can read and understand your SQL logic, relationships, and dependencies before it sends anything to the warehouse. This means that errors, like broken references or schema violations, can be flagged in real time while you're still developing.
Native Governance and Better Control – With Fusion, governance features like Model Contracts are enforced during compilation phase. This means that your schema and project standards can be validated locally so that dodgy code never reaches production.
State Aware Orchestration – Instead of running everything in a pipeline, dbt Fusion can now tell the state of your project - meaning it knows which models have underlying data that has changed, and which haven't. It then only runs necessary parts of the DAG that actually need to be ran, rather than just re-running everything from scratch every time.
The big headline result is lower costs, which is the true hook for most enterprises. It comes back, as it always does, to efficiency. You’re wasting fewer credits on project parsing or running models where their underlying data hasn’t actually changed.
New fun features (that make developers’ lives easier)
Real time linting – Immediate feedback on your SQL as you develop.
Column level lineage – The ability to track a single column across the entire DAG, so you can really see how a source fields gets transformed as it moves through your project.
Intelligent autocomplete & suggestions - It feels eerily like using autocomplete when I text on my phone, but now in VS Code with my SQL scripts. It is context aware and suggests functions, aliases, and name based on what already is happening in the project.
Automated Refactoring – When you rename columns, CTEs, or models – dbt Fusion recognises this and propagates your changes through the rest of your model as well as through all the downstream ref()s.
AI Powered Documentation – Really powerful for those of us (most of us, if we’re honest), who hate writing documentation. Since the engine understand the code, it can suggest help suggest descriptions for our columns and models.
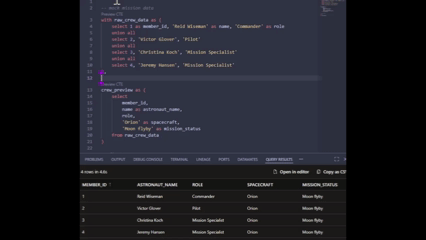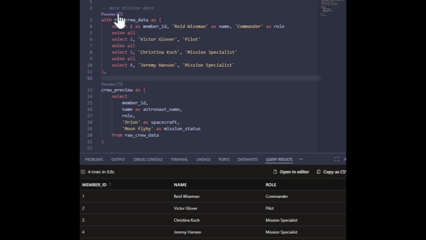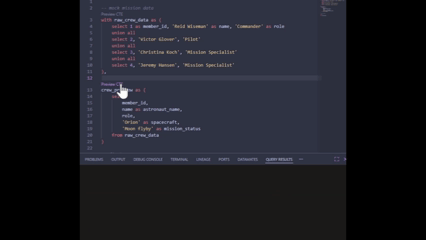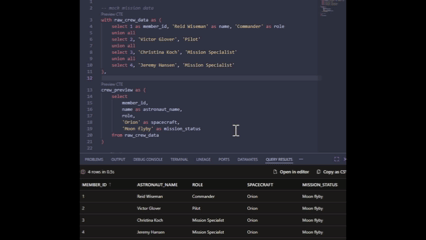
My personal favourite feature: Previewing CTEs
This is the one I’ve been loving the most. Because the engine now understands your SQL, you can preview individual CTEs in your model without running the whole thing. This has really allowed me to debug complex logic much faster, and without having to go externally to test in my warehouse directly.
Final Thoughts
dbt Fusion feels like a much needed catch up to the scale most companies are wanting to work at. We’re moving into an era of more intelligent development where the engine does most of the heavy lifting for us; by leaning on static analysis, it finally understands the logic we’re writing, making the whole process much more efficient.