

3 August 2015
Many technology partners within the sporting environment, such as Opta, Prozone and Tracab, provide clubs with their data in .XML files. These XMLs usually provide a more granular level of detail than what is available via their software packages or .csv exports. This extra level of detail ranges from more in-depth descriptions of events through to X/Y co-ordinates describing event locations, thus providing more context to the data and enabling a deeper level of insight to be gained. But here comes the problem, many sports clubs do not have the personnel with the required skill-set or the tools to parse the XML files from their seemingly confusing state (see Opta example above) to something that is comprehensible not only by the coaches, analysts, sport scientists and other backroom staff, but also by their visualization tools, such as Tableau.
But here comes the problem, many sports clubs do not have the personnel with the required skill-set or the tools to parse the XML files from their seemingly confusing state (see Opta example above) to something that is comprehensible not only by the coaches, analysts, sport scientists and other backroom staff, but also by their visualization tools, such as Tableau. The tag <MatchData> contains all of the match information regarding one particular football match (the ID of the match, the date and time of the match etc…). The end of this MatchData “element” is then distinguished by the tag </MatchData>.Within this <MatchData> element there is a further level of detail, in this instance there are the tags <MatchInfo>, <Stat> and <TeamData>, each of these are known as a “child”, with <MatchData> being the “parent”. (You may also note that the “child” tag <MatchInfo> also has a child of its own <Date>).The structure of the XML file will be described in a schema that the author (in this case Opta) will provide. This schema describes the layout of each file as well as any relevant definitions.
The tag <MatchData> contains all of the match information regarding one particular football match (the ID of the match, the date and time of the match etc…). The end of this MatchData “element” is then distinguished by the tag </MatchData>.Within this <MatchData> element there is a further level of detail, in this instance there are the tags <MatchInfo>, <Stat> and <TeamData>, each of these are known as a “child”, with <MatchData> being the “parent”. (You may also note that the “child” tag <MatchInfo> also has a child of its own <Date>).The structure of the XML file will be described in a schema that the author (in this case Opta) will provide. This schema describes the layout of each file as well as any relevant definitions.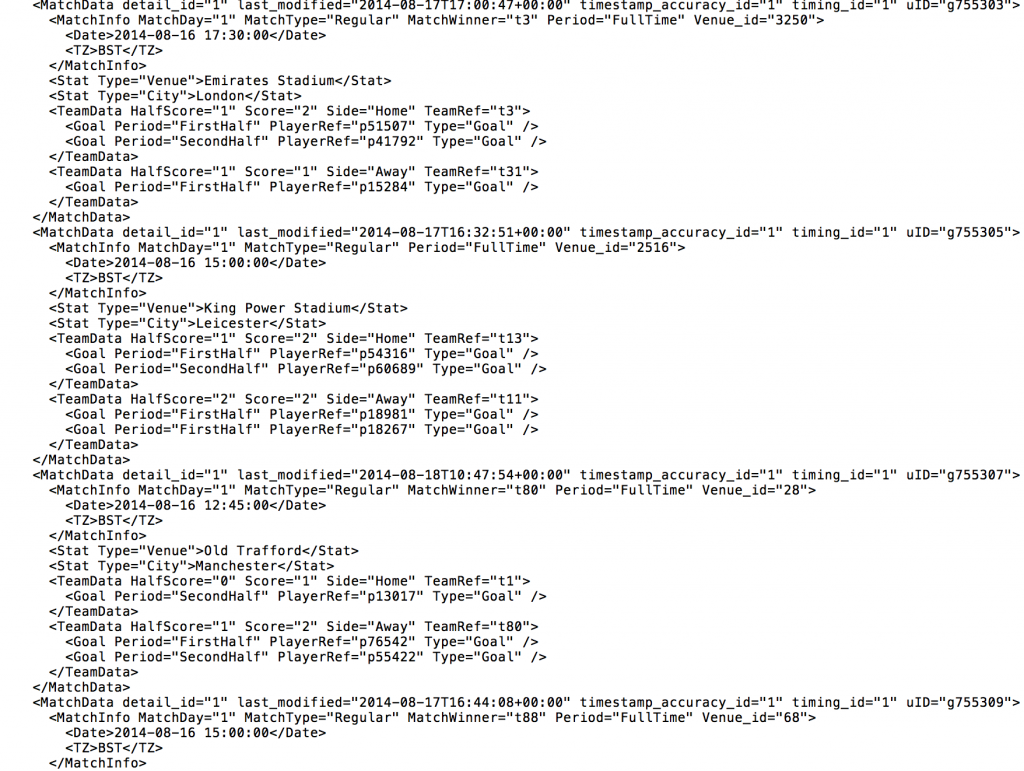 Into this….
Into this….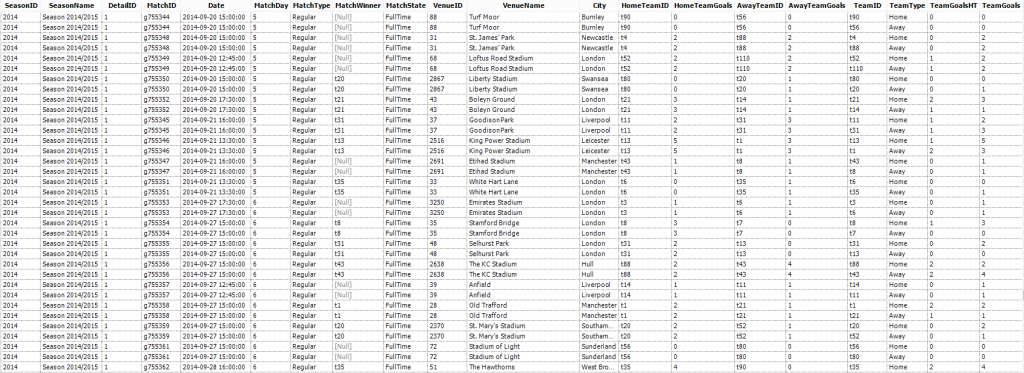 First we need to introduce our XML file to the workflow.
First we need to introduce our XML file to the workflow.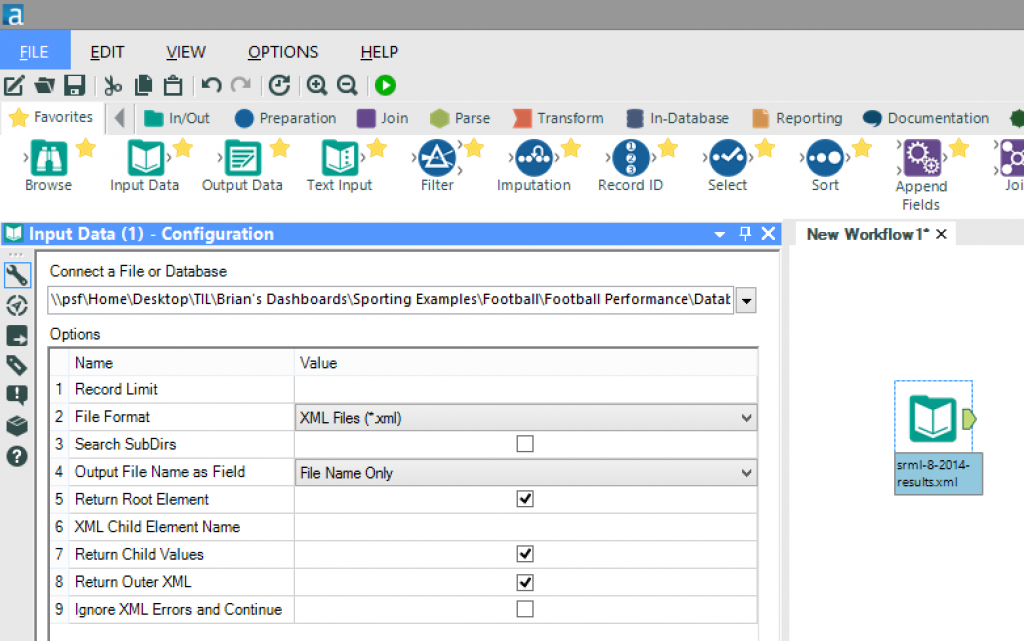 Use the “Input Data” tool and browse to the required Opta F01 file and then we need to configure the settings in the configuration pane. The key settings to note in this workflow are:
Use the “Input Data” tool and browse to the required Opta F01 file and then we need to configure the settings in the configuration pane. The key settings to note in this workflow are: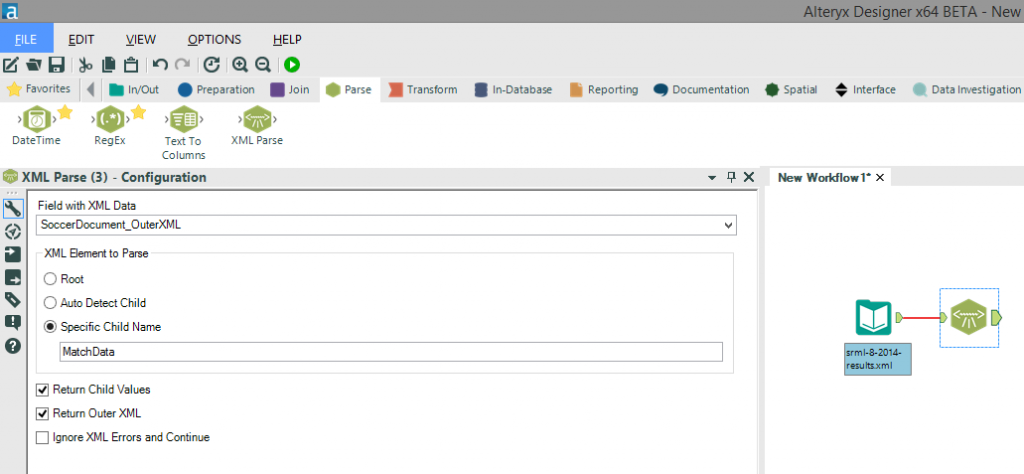 Now, before going any further, I want to introduce you to the “Select” tool. This tool enables us to change the data type of each field, rename the fields and remove any unwanted fields (as shown in the screenshot below) – this will speed up the processing of the data as well as making the output less confusing with unrequired fields.
Now, before going any further, I want to introduce you to the “Select” tool. This tool enables us to change the data type of each field, rename the fields and remove any unwanted fields (as shown in the screenshot below) – this will speed up the processing of the data as well as making the output less confusing with unrequired fields.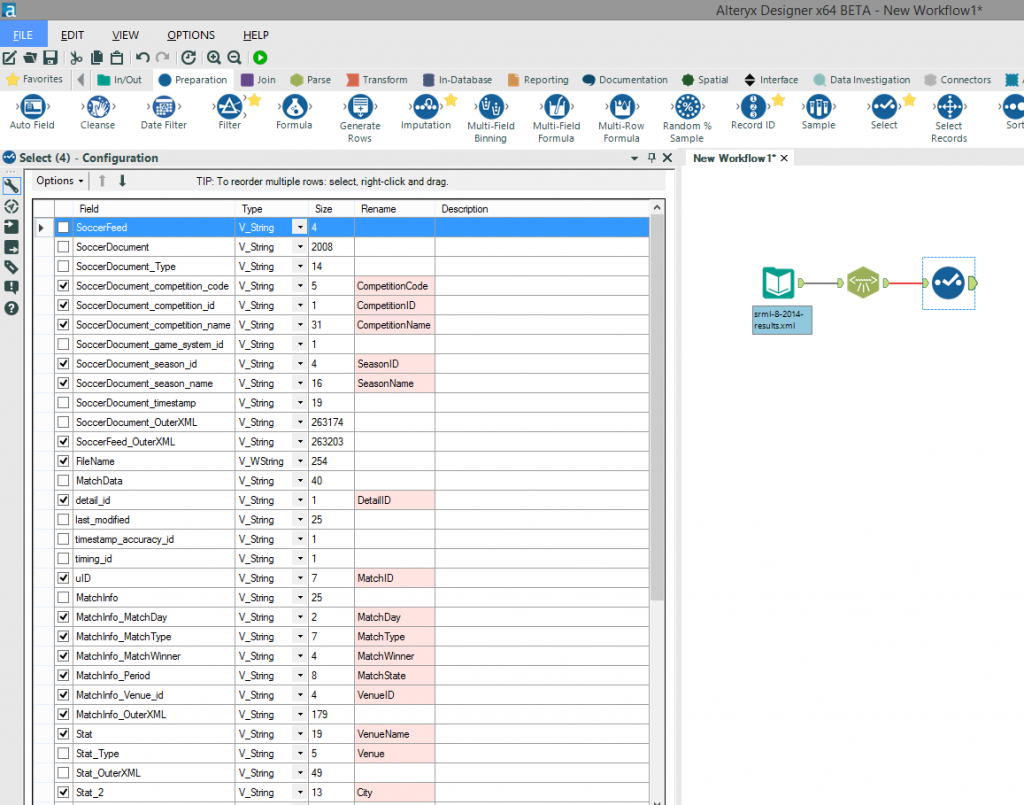 It’s then a case of repeating this process using the “XML Parse” and “Select” tools until you have parsed all of the required fields (in this case “MatchInfo_OuterXML” and “MatchData_OuterXML”) and have renamed and removed any unwanted fields.
It’s then a case of repeating this process using the “XML Parse” and “Select” tools until you have parsed all of the required fields (in this case “MatchInfo_OuterXML” and “MatchData_OuterXML”) and have renamed and removed any unwanted fields.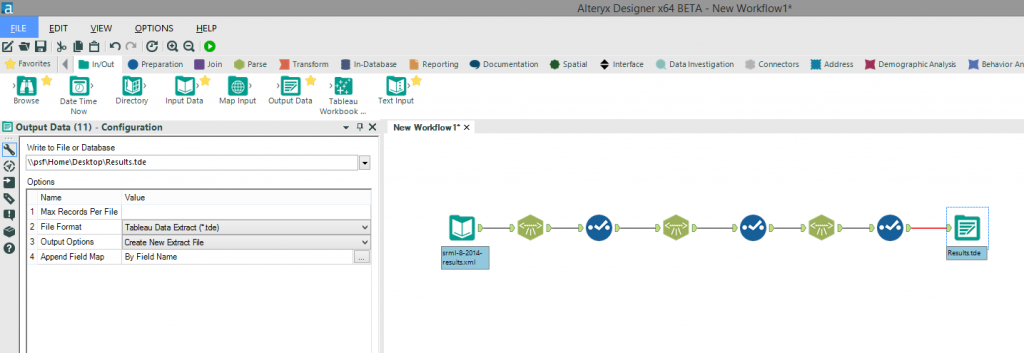 We can then output the parsed XML to a .tde file ready for use in Tableau (there are also other file format options for the output including .xls).The full workflow can be downloaded here.
We can then output the parsed XML to a .tde file ready for use in Tableau (there are also other file format options for the output including .xls).The full workflow can be downloaded here.
 But here comes the problem, many sports clubs do not have the personnel with the required skill-set or the tools to parse the XML files from their seemingly confusing state (see Opta example above) to something that is comprehensible not only by the coaches, analysts, sport scientists and other backroom staff, but also by their visualization tools, such as Tableau.
But here comes the problem, many sports clubs do not have the personnel with the required skill-set or the tools to parse the XML files from their seemingly confusing state (see Opta example above) to something that is comprehensible not only by the coaches, analysts, sport scientists and other backroom staff, but also by their visualization tools, such as Tableau.What is an XML file?
A quick google of “What is an XML file” will provide you with everything you could ever wish to know about XML files. But for the purpose of this blog post, all you need to know is this:An XML file is a plain text file, where tags are used to mark the start and end of the text that they define.For example, let’s take a snippet of an Opta F01 XML file (below). The tag <MatchData> contains all of the match information regarding one particular football match (the ID of the match, the date and time of the match etc…). The end of this MatchData “element” is then distinguished by the tag </MatchData>.Within this <MatchData> element there is a further level of detail, in this instance there are the tags <MatchInfo>, <Stat> and <TeamData>, each of these are known as a “child”, with <MatchData> being the “parent”. (You may also note that the “child” tag <MatchInfo> also has a child of its own <Date>).The structure of the XML file will be described in a schema that the author (in this case Opta) will provide. This schema describes the layout of each file as well as any relevant definitions.
The tag <MatchData> contains all of the match information regarding one particular football match (the ID of the match, the date and time of the match etc…). The end of this MatchData “element” is then distinguished by the tag </MatchData>.Within this <MatchData> element there is a further level of detail, in this instance there are the tags <MatchInfo>, <Stat> and <TeamData>, each of these are known as a “child”, with <MatchData> being the “parent”. (You may also note that the “child” tag <MatchInfo> also has a child of its own <Date>).The structure of the XML file will be described in a schema that the author (in this case Opta) will provide. This schema describes the layout of each file as well as any relevant definitions.I want my data!
So now we have the basics, let’s create our Alteryx workflow to turn this….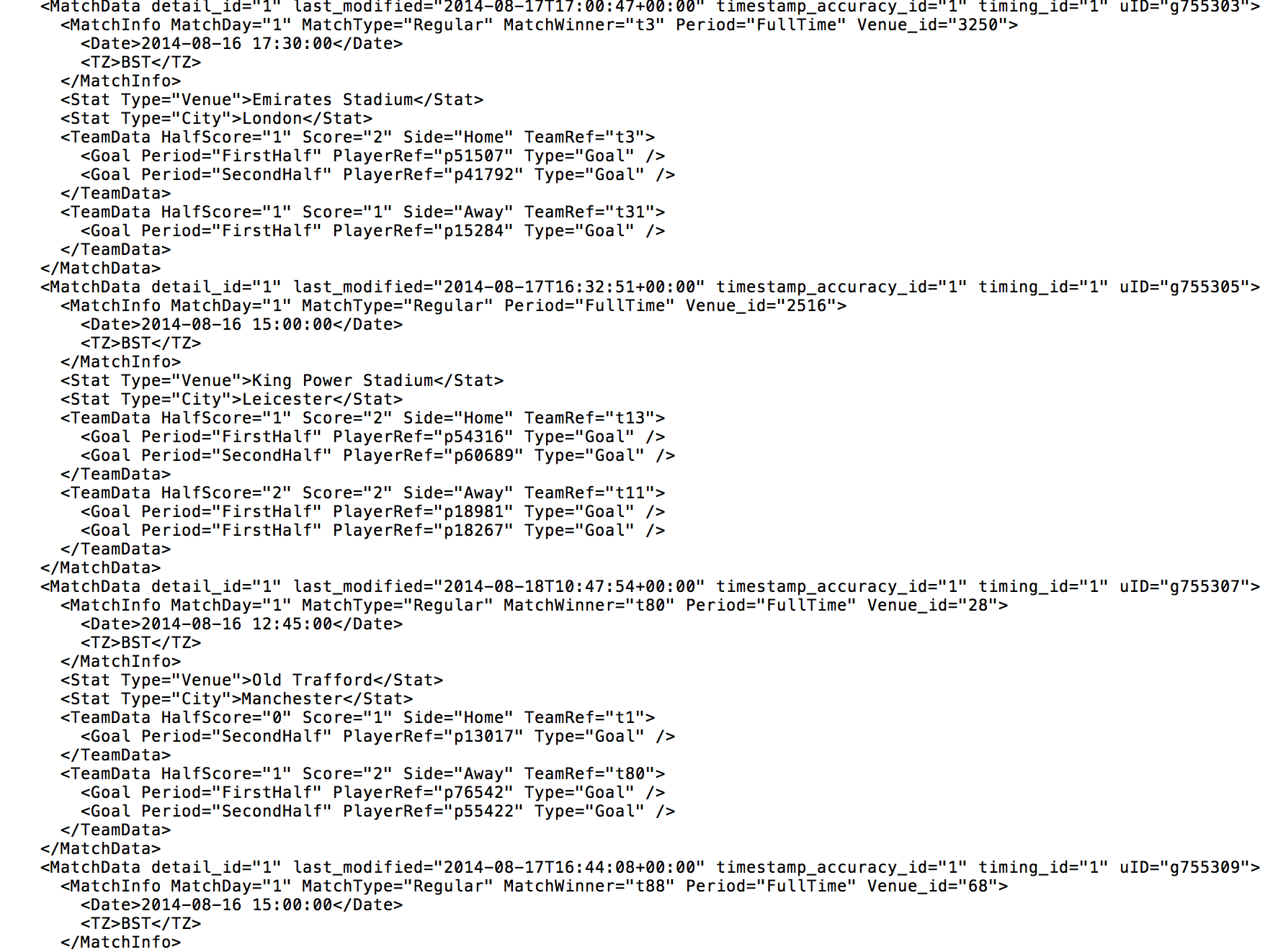 Into this….
Into this….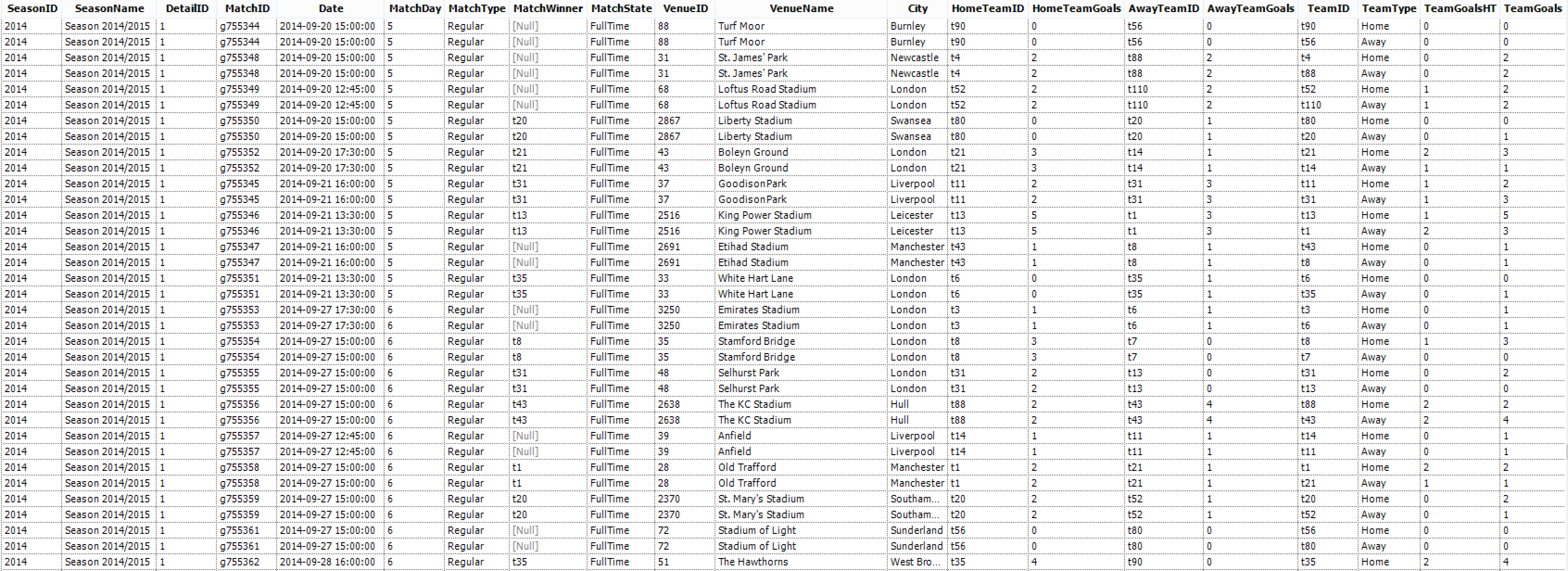 First we need to introduce our XML file to the workflow.
First we need to introduce our XML file to the workflow.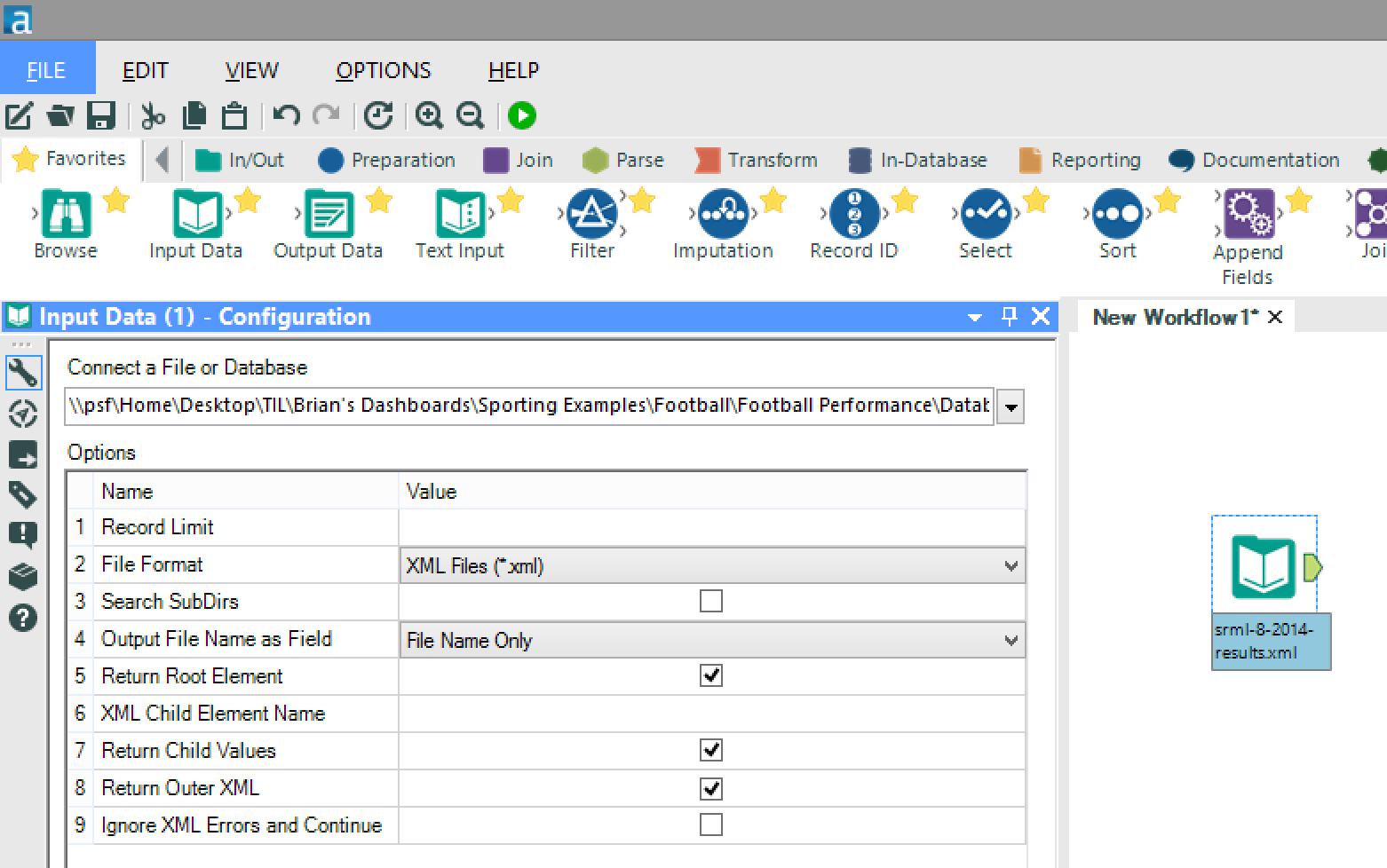 Use the “Input Data” tool and browse to the required Opta F01 file and then we need to configure the settings in the configuration pane. The key settings to note in this workflow are:
Use the “Input Data” tool and browse to the required Opta F01 file and then we need to configure the settings in the configuration pane. The key settings to note in this workflow are:- File Format – ensure it is set to XML
- Output File Name as Field – we are going to bring through the filename as a reference in this workflow, although this wouldn’t be required.
- Return Root Element – ensure this is ticked as this will bring back the initial parent element from the F01 XML (this element contains the child elements - these include the competition and relevant details).
- Return Child Values – this will bring back the child values of the root element above (ie. English Premier League, 2015 etc…).
- Return Outer XML – ticking this option will bring through everything within the <SoccerDocument> for use in the next phase of this workflow
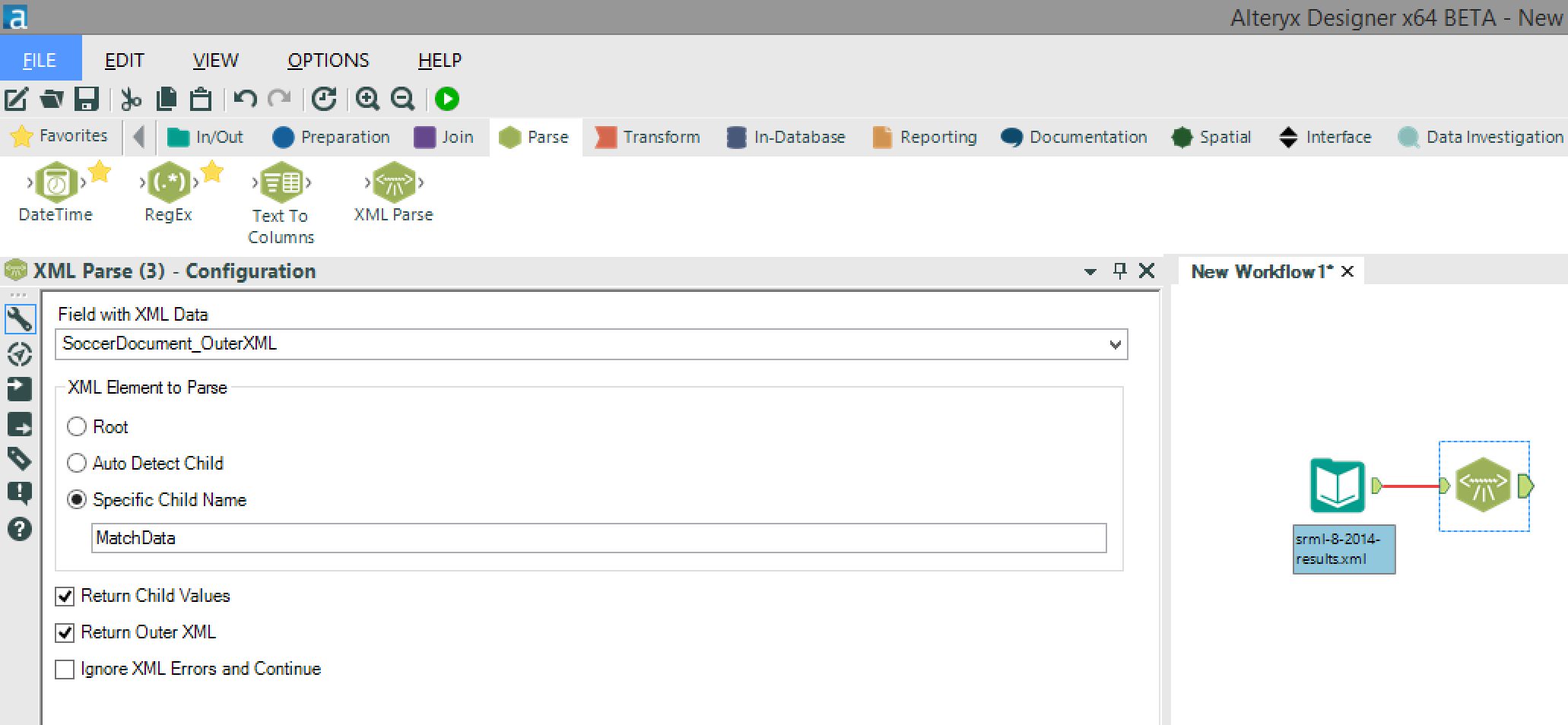 Now, before going any further, I want to introduce you to the “Select” tool. This tool enables us to change the data type of each field, rename the fields and remove any unwanted fields (as shown in the screenshot below) – this will speed up the processing of the data as well as making the output less confusing with unrequired fields.
Now, before going any further, I want to introduce you to the “Select” tool. This tool enables us to change the data type of each field, rename the fields and remove any unwanted fields (as shown in the screenshot below) – this will speed up the processing of the data as well as making the output less confusing with unrequired fields.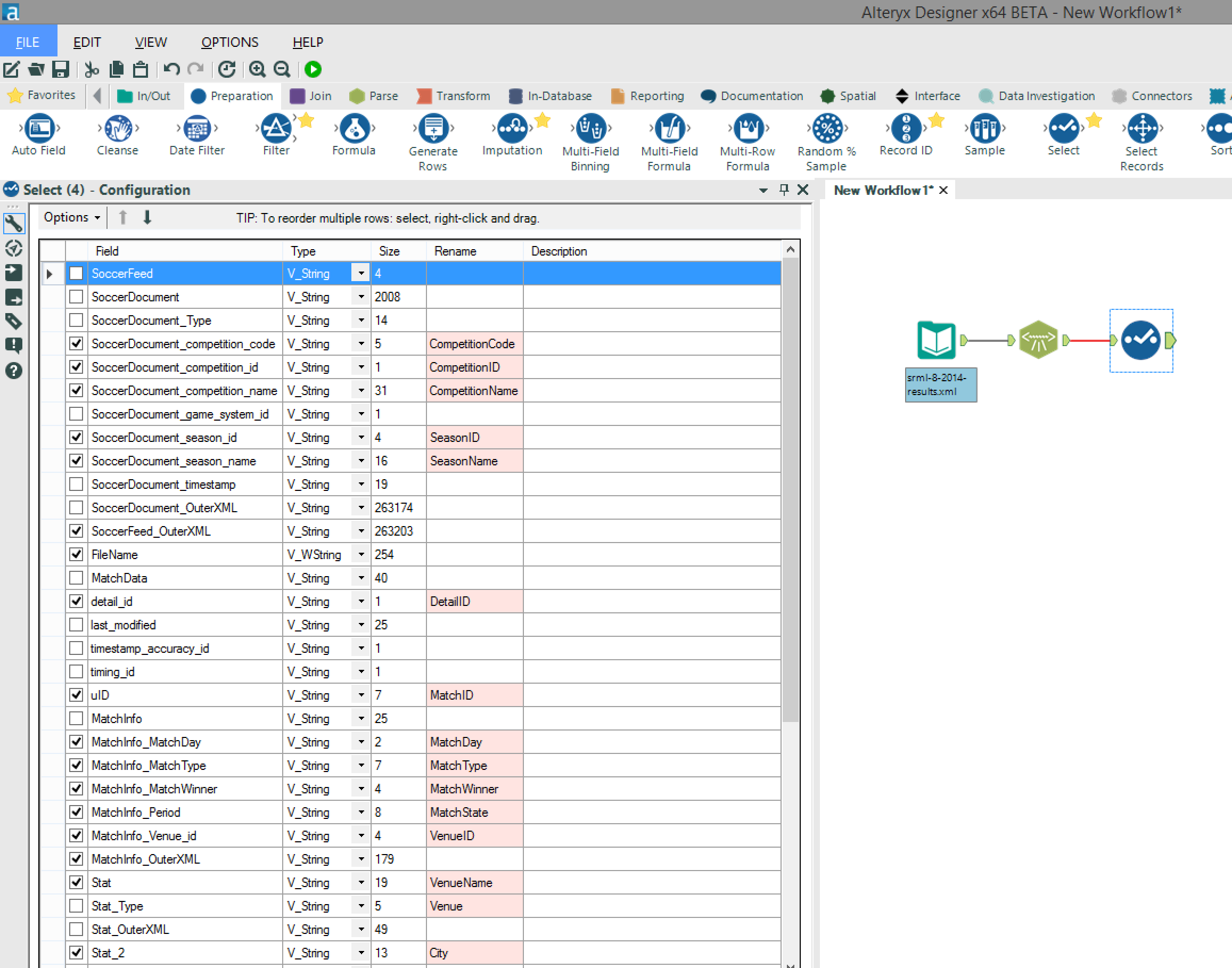 It’s then a case of repeating this process using the “XML Parse” and “Select” tools until you have parsed all of the required fields (in this case “MatchInfo_OuterXML” and “MatchData_OuterXML”) and have renamed and removed any unwanted fields.
It’s then a case of repeating this process using the “XML Parse” and “Select” tools until you have parsed all of the required fields (in this case “MatchInfo_OuterXML” and “MatchData_OuterXML”) and have renamed and removed any unwanted fields.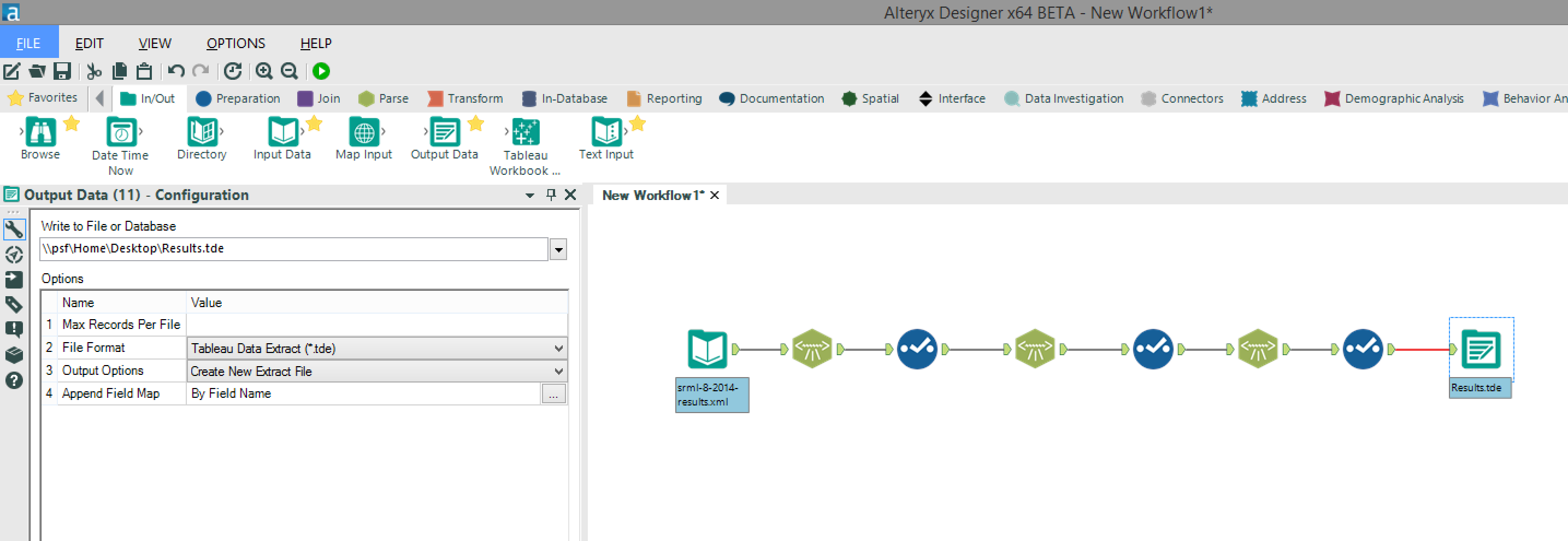 We can then output the parsed XML to a .tde file ready for use in Tableau (there are also other file format options for the output including .xls).The full workflow can be downloaded here.
We can then output the parsed XML to a .tde file ready for use in Tableau (there are also other file format options for the output including .xls).The full workflow can be downloaded here.